条件随机场及其在序列标注中的应用
条件随机场
背景
在序列建模中的马尔可夫方法一文中最后,我们介绍了最大熵马尔可夫模型,它将最大熵模型与马尔可夫链相结合,在局部状态转移决策中融入了丰富的特征表达能力。同时,也举出了它存在标签偏置这一严重问题,每个状态转移的条件概率需在局部时间步完成归一化,导致模型倾向于选择具有更少后续状态的标签路径,这种局部归一化机制会扭曲全局最优决策。为克服这一局限性,条件随机场应运而生。
介绍
CRF采用无向图模型结构,通过全局归一化策略将整个标签序列的条件概率建模为单一能量函数,不仅消除了局部归一化带来的偏差,还允许模型在更广阔的特征空间中进行全局优化。这一特性使其成为自然语言处理的基础模型,广泛用于中文分词、命名实体识别、词性标注等标注场景。
此外,CRF的另一个显著优势在于特征建模的灵活性,可支持任意形式特征模版设计,且能无缝融合深度学习提取的高阶语义特征。近年来,CRF与神经网络的结合催生了BiLSTM-CRF、BERT-BiLSTM-CRF等混合架构,CRF层在利用特征在最后进行全局最优解码,显著提升了复杂标注任务的性能表现。
前置知识
随机过程 vs 随机场
场:场是一个将空间或时空中的每个点映射为一个量(标量、向量或张量)的函数。比如,
随机场:随机场是将场的概率扩展到概率论的结果。每个空间点对应的不再是确定的值,而是一个随机变量。用数学语言描述,随机场是一个随机变量的集合,每个随机变量对应一个索引点(空间坐标或者时间点)。记作
随机过程:描述随机变量随时间变化的过程。实际上,是一种特殊的随机场,索引集为一维时间。记作
马尔可夫随机场
在之前的文章中我们讲到,马尔可夫过程是一个具有马尔可夫性质的随机过程。同样的,马尔可夫随机场就是随机变量满足马尔可夫性质的随机场。从随机过程推广到随机场,依赖关系从时间上的先后顺序到空间上的邻域结构。由于领域之间的关系是双向的,这使得马尔可夫随机场本质上对应的是一种无向图模型,也称为概率无向图模型。
用数学语言描述,定义在图
无向图的因子分解
不同于有向图模型使用条件概率来表达联合分布,无向图模型由于边没有方向,难以为每个变量明确指定“条件变量”与“被条件变量”,因此无法用条件概率的形式来参数化联合分布。为了解决这个问题,无向图模型采用因子分解的方式,将联合概率表示为图中团上的一组非负局部函数(势函数)的乘积,从而借助图的局部结构来建模全局分布。
团与最大团:
团:图上的一个完全子图,即任意两个顶点之间都存在边。
最大团:包含最多顶点的团。
具体地,还是刚才那个无向图,整个随机场的联合概率可以表示为:
线性链条件随机场
现在我们再来看条件随机场,和MEMM一样都是对条件概率
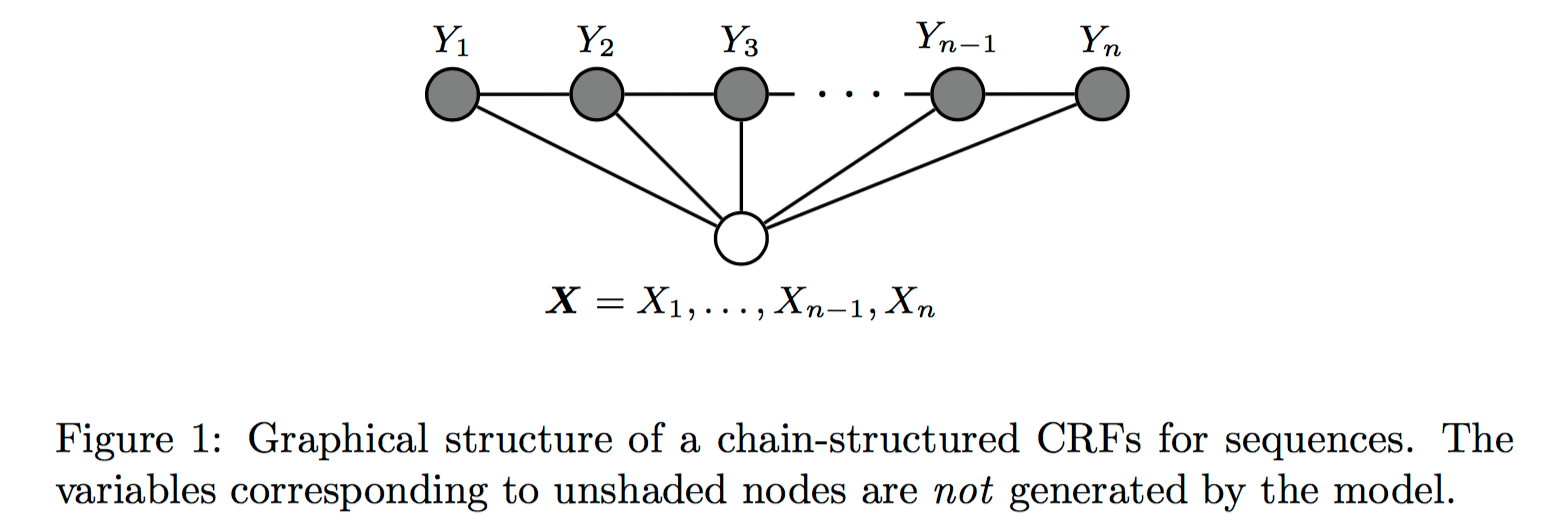
概率建模
线性链CRF假定在给出
举例:一个A-B-C的链式结构,它的两个极大团为
所以联合概率可以分解为:
参数说明
定义在边上的特征函数,称为转移特征;依赖当前和前一个位置;刻画标签之间的依赖;只有0/1两种取值。 定义在节点上的特征函数,称为状态特征;依赖于当前位置;刻画标签与观测之间的依赖;只有0/1两种取值。 表示权重参数, 依然为归一化因子。
求解
对于给定序列和预测的标签序列,对应的得分(未归一化的对数概率)可以写为:
求解过程就是使用动态规划算法找出使得上述得分最高的预测序列
BiLSTM-CRF
Bidirectional LSTM-CRF Models for Sequence Tagging 该论文提出了将BiLSTM与CRF结合起来进行序列标注的模型。在本文之前,有使用RNN-CRF和单独使用LSTM进行命名实体识别,本文首次提出了BiLSTM-CRF,并对单向LSTM-CRF也进行了对比分析,启发了后续研究者对于CRF的使用,具有里程碑式的意义。
具体流程
输入特征提取
提取单词特征(小写单词、词嵌入)、拼写特征和上下文特征,并将其拼接为每个时间步的输入向量。
具体地,单词特征包括原始单词的表示(one-hot编码或者词嵌入);拼写特征包括“是否以大写字母”,“是否全部是大写字母”,“前缀或者后缀”这些二值特征或者离散特征;上下文特征是将多元特征组成的一个高维向量。这些特征经过输入层降维并拼接成统一的特征向量,作为BiLSTM每个时间步的输入。
BiLSTM层处理
BiLSTM捕捉每个时间步过去的信息和未来的信息,并对其拼接形成丰富的上下文表示,
具体地,对于每一个隐藏状态
CRF层优化
BiLSTM层会输出一个得分矩阵,即为发射得分。CRF层引入状态转移矩阵
转移矩阵
对比分析
BiLSTM的作用
结合前向和后向的LSTM,分别处理序列过去和未来的信息,拼接成完整的上下文表示。
BiLSTM通过学习输入特征的深层表示,减少了对人工特征工程的依赖。通过实验表明,即使去除拼写特征和上下文特征,整个模型的下降也较小,说明其从原始输入中提取有效特征的能力。
CRF的作用
是模型的标签预测优化组件,负责建模标签之间的依赖关系。
BiLSTM单独使用时,每个标签预测都是独立的。也就是说,我们只关注了当前词属于哪个标签概率,CRF在整个序列上建模标签之间的全局依赖。通过CRF优化整条序列的联合概率,避免不合法的标签组合。
实验也表明,CRF层显著提升了标签序列的结构化预测能力。LSTM-CRF/BiLSTM-CRF比单独的LSTM/BiLSTM性能更好。
BiLSTM-CNNs-CRF
End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF 在BiLSTM-CRF的基础上,新增加了CNNs模块。CNNs的作用主要体现在局部字符级别特征提取上,尤其是在处理词级输入的字符嵌入时。在BiLST编码之前构建更丰富的词向量表示。
创新点
CNN层获得字符级特征表示
为什么做
在上文提到的BiLSTM-CRF的特征提取部分,可以观察到诸如 是否混合字母和数字、是否以’s结尾等字符级别的拼写特征。引入CNN层的目的就是为了通过神经网络自动提取单词的字符级信息,如形态学特征(前缀、后缀),以增强对OVV和形态变化的处理能力。
怎么做
每个单词看作是一个由字符组成的序列,每个字符表示成一个随机初始化的字符嵌入。使用若干CNN对字符嵌入进行处理,提取局部特征,并生成固定维度的字符级表示。
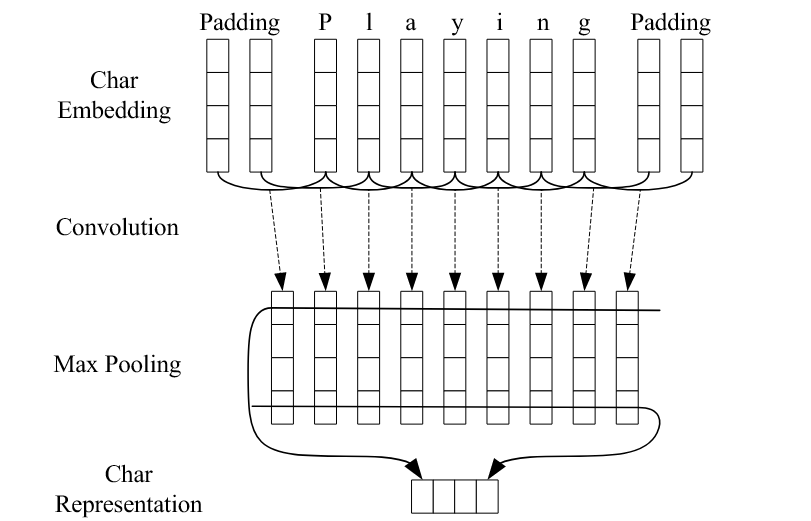
有什么用
首先,相比传统的手工特征,CNN能够自动学习字符级模式,且无需额外的字符类型特征,是名副其实的“端到端”模型,通用性强。
其次,普通词嵌入对罕见词的效果差,但字符级CNN能从构词规律中提取有用信息,如以itis为结尾的通常是疾病名。虽然在上文中的拼接输入特征时,也会使用到词的前后缀信息,但表达能力有限。
 微信
微信 支付宝
支付宝